データ科学と人工知能
Contents
1. データ科学と人工知能¶
1.1. データ科学における解析法¶
データ科学と機械学習の関連についてまとめます.
1.1.1. データ科学¶
データ科学という用語が意味するものはとても曖昧で漠然としています.データ科学は第 4 の科学とかって言われていますがこれまでの科学(実験科学,理論科学,計算機科学)でもデータ使っていたと思います.
一方で,半導体技術の向上やインターネットの繁栄により大量のデータを扱えるようになると共にデータ科学が流行を迎えたという背景を考慮すると,従来の科学とデータサイエンスの差異は扱うデータの量にあるという側面はありそうです.
すなわち,データ科学は大量のデータを処理し,そこに内包される知見を抽出する学問という側面を少なくとも持つのかもしれません.そのような観点において,従来の科学で用いられてきた紙とペン,また,表計算ソフトウェアはデータ科学で用いられる解析手法としては役者不足です.データ科学分野において,大量のデータに内包される知見を抽出する手段として用いられるものは機械学習法に他なりません.
1.1.2. 機械学習¶
機械学習法は人工知能を作り上げる方法です.現在までに人類が開発に成功し活用している人工知能は特化型人工知能と呼ばれる種類の人工知能です.それは,「何らかの入力に対して何らかの出力をするアルゴリズム」と「そのアルゴリズムが有するパラメータ」,このふたつの要素によって構成されます.
人工知能を教育する過程では,まっさらな人工知能に対して(通常)何度も何度もデータを繰り返し入力し,このパラメータを最適なものへと変化させます.何らかの入力に対して何らかの出力をするアルゴリズムには様々なものがあります.深層学習で主に利用されるニューラルネットワークやその他にも決定木,サポートベクトルマシン,主成分分析法等の様々な手法があります.
Note
アトムやドラえもんみたいな汎用的に問題を解決できる存在のことは汎用人工知能といいます.また,精神を宿したような存在のことをジョン・サールという人は強い人工知能と表現しましたが,アトムとかドラえもんは汎用人工知能であり強い人工知能です.人が思い描く人工知能とはこういった存在であって,このような単なる予測器を人工知能と呼ぶことに抵抗を持つ人は多いですが,特化型人工知能と正確に呼べば納得してもらえるかもしれません.
Note
機械学習法は人工知能がデータに適合するように人工知能を成長させる方法です.どのような人工知能が完成するかは利用したデータに依ります.
Note
人工知能という言葉は色々なものを再定義しており,ニューラルネットワークを人工知能というのならば,高校数学で習得する最小二乗法を用いて求める線形回帰直線も人工知能です.
1.2. 機械学習法の種類¶
人工知能にデータを読ませ成長させる過程を学習と言いますが,学習方法にはいくつかの種類があります.機械学習法は教師あり学習法(supervised learning),教師なし学習法(unsupervised learning),強化学習法(reinforcement learning)の 3 つに大別されます.これらの学習法は,どれがどれに対して優れていて,どれがどれに対して劣っている等の比較をするような対象ではありません.これらは,与えられた問題を解決するためにどのような人工知能を構築したいのかという観点からそれに適した方法を選択するものです.
1.2.1. 教師あり学習法¶
教師あり学習法では,入力データとそれに紐づいた教師データの組み合わせを利用します.例えば,画像認識の問題を考えるとすると,「ゴリラが写っている画像」と共に「ゴリラ」という情報を用います.この場合,「ゴリラが写っている画像」が成長させたい人工知能に処理させる入力データで,「ゴリラ」という情報は人工知能にこの画像にはゴリラが写っていることを教えるための教師(supervisor)データです.教師データはラベル,正解,ターゲットデータ等とも呼ばれることがあります.
このような入力と教師データのペアをいくつも用意し,それらを人工知能に学習させます.教師あり学習の目的は,そのようにして構築した人工知能に新たな入力データが入力された場合に,そのラベルを予測させることです.
ここでは,ラベルを予測させる分類問題を例にしましたが,数値を予測させることも可能で,回帰問題にも利用可能です.教師あり学習法で成長させられる機械学習モデルとしては,ニューラルネットワーク,サポートベクトルマシン,線形回帰式,決定木をはじめとして様々なものがあります.
Note
回帰問題は人工知能に何らかの実数の値を出力させる問題で,分類問題は人工知能にクラスを出力させる問題です.
Note
機械学習モデルとは人工知能のことです.機械学習法によって成長させられるモデルのことです.
1.2.2. 教師なし学習法¶
教師なし学習法で成長させた人工知能は入力データに対して何かの予測値を出力するようなものではありません(最終的な産物としてそのような出力をするように設計することも場合によっては可能).教師なし学習法では教師あり学習法で用いるような入力データと教師データの組み合わせを利用しません.
教師なし学習法で機械学習モデルに学習させるデータは入力データのみです.教師なし学習法で成長させられる人工知能は与えられたデータに存在する傾向を把握するために用いられることが多いです.類似の性質を持つデータを集めるクラスタリングや,人の能力では理解できないような高次元に存在するデータを可視化することや,データの特徴の抽出等に利用されます.教師なし学習法のアルゴリズムとして用いられるものとしては,K-means,階層的クラスタリング法(単連結法をはじめとする階層的にデータを分類する手法の総称),主成分分析法,自己組織化マップ(ニューラルネットワークの一種)等の様々なものがあります.
1.2.3. 強化学習法¶
強化学習法は教師あり学習法と完全に独立な学習法ではありません.正解の情報を利用するという点においては教師あり学習法と同様です.しかし実際の強化学習法で行っていることは教師あり学習法で行っていることと様々な部分で異なっています.
強化学習法で用いる正解の情報は報酬(報酬を合計した価値も正解の情報)と呼ばれます.これに加えて強化学習法で成長させる人工知能はエージェントと呼びます.エージェントは何らかの環境に作用して,その環境に影響を及ぼす行動をすることによって得られる価値を最大化するように成長させられます.このときの価値は教師あり学習法で用いられるような正解データのように即時的に正解または不正解を判断できるようなものではなく,一連の行動の結果に対して与えられるものです.この点において,教師あり学習法と強化学習法は異なります.
例えば,2人のキャラクター同士が何らかのステージで戦う格闘ゲームを例にすると,最大の報酬が与えられるのは敵であるキャラクターを倒したときであって,戦いの過程においてパンチを繰り出せとか,必殺技を放て等の個々の行動に対する正解は提示されません.ダメージをたくさん与える行為により大きな報酬を設定することはあります.
強化学習法は現在最も活発に開発研究が行われている学習法であると言っても過言ではなく,日々様々な手法が考案されています.例えば,深層ニューラルネットワークを利用して構築されたエージェントは一部のゲームにおいては人以上の性能を示しています.強化学習法で利用されるアルゴリズムには,動的計画法,や Q 学習法等があります.深層学習法と相性が良く活発に研究されているものは Q 学習法です.
Note
このコンテンツで主に扱うものは教師あり学習法です.
1.3. 機械学習をする際の心構え¶
機械学習を利用した研究開発を行う際に最も大切なことは複雑なプログラムを作れるとかプログラミングを効率的にできるとか複雑な機械学習アルゴリズムを理解できるとかではありません.現在の機械学習の研究開発者が最も意識すべきことは人工知能を過学習させないこと,人工知能を正当に評価することです.
1.3.1. 過学習¶
機械学習法は,人工知能にデータを繰り返し学習させることで人工知能をその与えられたデータに適合させます.構築された人工知能に求められることはその「与えられたデータ」以外の新たな別のデータに対して良い予測性能を発揮できることです.
このとき「与えられたデータ」と「新たな別のデータ」の性質が同等とは限りません.もし人工知能が「与えられたデータ」に過剰適合してしまい,「新たな別のデータ」に対して良い予測性能を発揮できないとき,その人工知能は過学習を起こしているというように表現されます.人工知能の開発の際に最も大きな問題となるのが過学習です.人工知能開発に要する時間の大半は過学習を起こさないための工夫をしている時間であると言っても過言ではないです.
Note
人工知能が学習データのみに過剰適合することを過学習と呼びます.
1.3.2. データ分割の大切さ¶
過学習を避けるため,また,構築した人工知能を正当に評価するために最も大切なことであるデータセットの構築方法を紹介します.データセットは以下のように分割します.はじめに,元の全データを「学習データセット(learning dataset)」と「テストデータセット(test dataset)」に分けます.さらに,学習セットを人工知能の成長(アルゴリズムが持つパラメータの更新)のためだけに利用する「トレーニングデータセット(training dataset)」と学習が問題なく進んでいるか(過学習や未学習がおこっていないか)を確認するために利用する「バリデーションデータセット(validation dataset)」に分けます.
Note
バリデーションデータセットは開発データセット(development dataset)とも言います.

学習の際には学習データセットを利用して得られる結果だけを観察します.学習の際に一瞬でもテストセットにおける予測器の性能を観察するべきではありません.また,「独立であること」もしっかり定義すべきです.データが互いに独立であるとは,機械学習の文脈においては「学習データセットに含まれるデータとテストデータセットに含まれるデータが,互いに関連を持たないこと」です.例えば,画像に含まれている文字を予測する人工知能を様々な人が書いた文字を取り扱うために利用するのなら,手書き文字の画像を書いた人が学習データセットとテストデータセット間で異なっていなければなりません.
Note
統計学における独立同分布からの標本抽出の考え方です.
新たな人工知能を開発してそれを公開する場合,普通,その人工知能の性能をベンチマークし論文や学会で発表します.その性能を評価するために使うデータセットがテストデータセットです.もしこのテストデータセットが学習データセットと同じような性質を持っているのであれば,その人工知能は新たなデータを処理するときに期待されるような性能を発揮できないかもしれません.
学習データセットとテストデータセットが独立でないのならば,学習データセットに過剰適合させた人工知能では,あたかもとても良い性能をしているように見えてしまいます.人工知能の実際の現場での活用方法を鑑みるに,人工知能はある特定のデータにだけではなく,様々なデータに対応できる汎化能力を持たなければなりません.
Note
人工知能の開発の研究に関して,その全行程において,データセットの正しい分割は何よりも大切なことです.従来からの科学の分野で研究を続けている人達にとって,機械学習に対する信頼度は未だ低い場合があります.機械学習をやる人がここを適当にやり続ける限り,「機械学習なんて眉唾」みたいな意見はなくならないことをご理解ください.
1.4. 機械学習の専門用語の説明¶
機械学習の分野では日々新しい言葉が作られていたり,様々な分野から機械学習の研究をしようとしている人がいたりするため,用語の用法にコンセンサスが取れていない場合があります.そこでこの節では機械学習に関する用語の説明をします.知らない単語に出会ったらこの節に戻って確認してください.
1.4.1. 予測器¶
予測器と人工知能は同じものを指します.機械学習法によって成長させる対象のことであり,機械学習を行った際の最終産物です.本体は「何らかの入力に対して何らかの出力をするアルゴリズム」と「そのアルゴリズムが必要とするパラメータ(母数)」です.このような特定の問題を解決するための人工知能は特化型人工知能といいます.
1.4.2. インスタンス¶
データセットにあるひとつのデータのことです.分野によってデータポイントと呼ばれることがありますが,時系列データを扱う際には別の意味でデータポイントという単語が用いられることがあり,インスタンスを使った方がより正確かもしれません.
1.4.3. 回帰問題と分類問題¶
教師あり機械学習法で成長させる人工知能を利用して解決しようとする問題は大きく分けてふたつあります.ひとつは回帰問題です.回帰問題は人工知能に何らかの実数の値を出力させる問題です.
一方で,分類問題は人工知能にクラスを出力させる問題です.クラスとは「A,B,C」とか「良い,悪い」のような何らかの分類のことです.各クラスの間に実数と他の実数が持つような大小の関係性は定義されません.これは例えば,「0 という手書きの数字が書かれている画像」と「1 という手書きの数字が書かれている画像」を分類するというような場合においても当てはまります.
このような問題の場合,人工知能の最終的な出力は 0 または 1 でありますが,これは人工知能にとって単なるシンボルであって,人工知能は「0 という手書きの数字が書かれている画像」が「1 という手書きの数字が書かれている画像」より小さいから 0 という出力をするのではなく,単に「0 という手書きの数字が書かれている画像」にある 0 というパターンが0というシンボルと類似しており,1 というシンボルと類似していないため,0 を出力するに過ぎません.
1.4.4. 入出力データ¶
入力データとは人工知能を成長させるため,または,開発した人工知能に予測をさせるために入力するデータです.インプットデータとも呼ばれます.ターゲットデータは教師あり学習の際に入力データとペアになっているデータです.教師データとも呼ばれます.出力データは入力データを人工知能に処理させたときに出力されるデータです.教師あり学習の場合,このデータの値がターゲットデータに似ているほど人工知能の性能が良いです.
1.4.5. エポック¶
用意したトレーニングデータセット(パラメータ更新にのみ用いるデータセット)の全部を人工知能が処理する時間の単位です.1 エポックだと全データを人工知能が処理したことになります.2 エポックだと 2 回ほど人工知能が全データを処理したことになります.学習の過程では通常,繰り返しデータを人工知能に読ませます.
1.4.6. 損失関数とコスト関数¶
損失(ロス)とは人工知能が出力する値とターゲット(教師)の値がどれだけ似ていないかを表す指標です.これが小さいほど,人工知能はターゲットに近い値を出力できることになります.よって,この損失を小さくすることが学習の目標です.損失を計算するための関数を損失関数(ロス関数)と言います.また,コストは損失と似ているものですが,正則化項(人工知能の過剰適合を防ぐために用いる値)を損失に加えた場合の小さくする目標の関数です.それを計算する関数をコスト関数と言います.損失関数とコスト関数はどちらも場合によって学習の目的関数となり得ます.
1.4.7. 正確度と精度¶
正確度とは英語では accuracy と記述されます.略記で ACC とも表現されます.真陽性,偽陽性,偽陰性,真陰性をそれぞれ \(a\),\(b\),\(c\),\(d\) とするとき正確度 \(u\) は以下の式で定義されます:
\(u=\displaystyle\frac{a+d}{a+b+c+d}\).
また,精度が英語で precision と記述されるものだとすると,人工知能の評価指標としての精度は positive predictive value(陽性適中率)のことを指していて,PPV と略記されます.精度 \(v\) は以下の式で定義されます:
\(v=\displaystyle\frac{a}{a+b}\).
つまり,これは陽性と予想した場合の数に対して本当に陽性であった場合の数の割合です.人工知能の性能を表現するために精度という単語を使う人がたくさんいます.精度は人工知能を評価するひとつの指標に過ぎません.しかも,この指標は正確度や MCC や F1 と比較して頑健な評価指標ではなく,人工知能の開発者が自由に調整できてしまう値です.これだけで人工知能の性能は評価不可能です.科学的な文脈においては,精度という単語を使いすぎないように気を付ける必要があるのではないでしょうか(多くの場合,性能というべきでしょう).その他の指標は以下の Wikipedia が詳しいです.
1.4.8. パラメータ¶
パラメータは人工知能を構成する一部です.機械学習法で成長させられるモデルは何らかの入力に対して何らかの出力をしますが,このモデルがその計算をするために必要とする値を持っている場合があり,それをパラメータと言います.機械学習ではアルゴリズム自体は変化させずに,パラメータを変化させることによって良い人工知能を作ろうとします.深層学習界隈では最急降下法によってパラメータは更新される場合が多いです.また,学習によって更新されるパラメータとは異なり,学習の前に人間が決めなければならないパラメータがありますが,これをハイパーパラメータと言います.ニューラルネットワークでは,活性化関数の種類であったり,各層のニューロンの数であったり,層の数であったりします.このハイパーパラメータすらも自動で最適化しようとする方法もあり,そういう方法を network architecture search(NAS)と言います.
1.4.9. 二乗誤差¶
あるベクトルとあるベクトルの距離です.損失関数として利用されます.
1.4.10. ソフトマックス¶
要素を合計すると 1 になるベクトルタイプのデータです.各要素の最小値は 0 です.これを出力する関数をソフトマックス関数と言います.入力ベクトルに対して入力ベクトルと同じ要素次元数のベクトル(ソフトマックス)を出力します.
1.4.11. パラメータ更新法¶
機械学習モデルのパラメータの更新の仕方には種類があります.一括学習はバッチ学習とも呼ばれます.人工知能を成長させるときにデータを全部読み込ませた後に初めてパラメータを更新します.逐次学習はオンライン学習とも呼ばれます.人工知能を成長させるときにデータを 1 個ずつ読み込ませ,その都度パラメータを更新する方法です.ミニバッチ学習は全データからあらかじめ決めた分のデータを読み込ませ,その度にパラメータを更新する方法です.ミニバッチ学習のミニバッチサイズが全データサイズと等しいならそれは一括学習で,ミニバッチサイズが 1 なら逐次学習です.
1.4.12. 早期終了¶
人工知能を成長させるときに,過学習(データへの過剰適合)が起こる前に学習を停止させることです.最もナイーブには,学習の最中に最も良い性能を示した値を記録しておき,その値を \(n\) 回連続で更新しなかった場合に学習を打ち切る方法があります.この \(n\) 回のことを patience と言います.
1.4.13. オプティマイザ¶
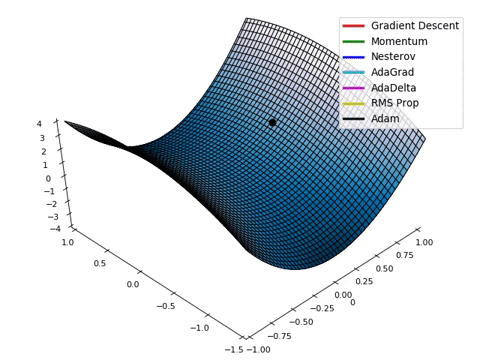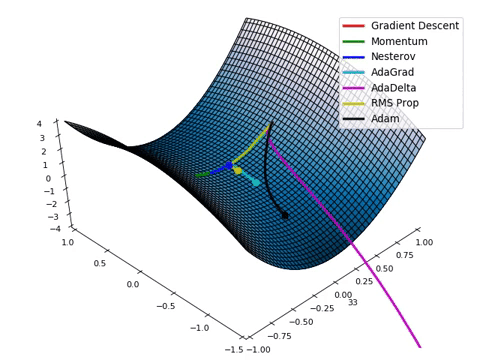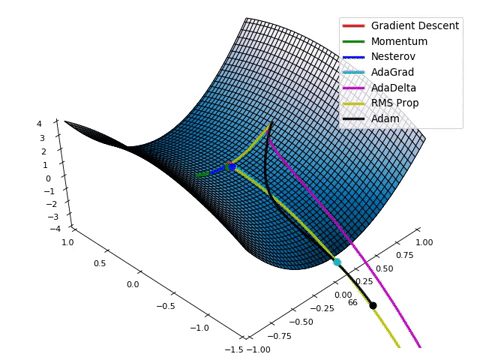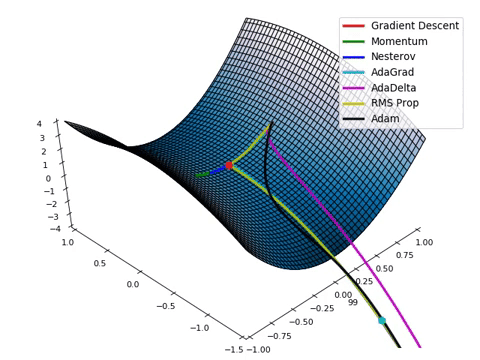
最急降下法は最もナイーブな最適化法のひとつです.学習をより良く(学習の速さを良くするとか局所解に陥り難くするとか)進めるために様々な最適化法が考案されています.深層学習で用いられる最適化法は基本的には最急降下法を改善した方法です.最急降下法やそういった最適化法のことをオプティマイザと言います.利用するオプティマイザによって学習の様子は劇的に変化します.以下の画像は停留点の中でも厄介な鞍点から,洗練されたオプティマイザがいかに早く抜け出せるかを動画にしたものです.
Note
終わりです.